Python3.6爬虫教程之五小项目模拟登陆CSDN(urllib高级用法)
1.登陆csdn的准备工作
1.安装抓包软件fiddler
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件)。 Fiddler 要比其他的网络调试器要更加简单,因为它不仅仅暴露http通讯还提供了一个用户友好的格式。——百度百科
在我们浏览网页,或者登陆网站的时候,fiddler软件可以记录下来我们的浏览器和服务器之间交互的数据信息,也就是我们常说的抓包工作,抓http数据。fiddler软件下载地址:http://www.downza.cn/soft/234727.html 下载后,直接安装即可。稍后我们将介绍fiddler软件在爬虫模拟登陆过程的使用方法。
2.安装BeautifulSoup4 解析库
我这里用的是Windows平台,电脑在装python3.6环境的时候,已经同时装好了pip3.首先 使用Windows+R键,然后输出cmd,打开cmd的dos框,输入pip3,用于判断pip3是否安装成功,安装成功后,将出现下面的信息。如果没有安装成功,则请自行百度pip3的安装方法。
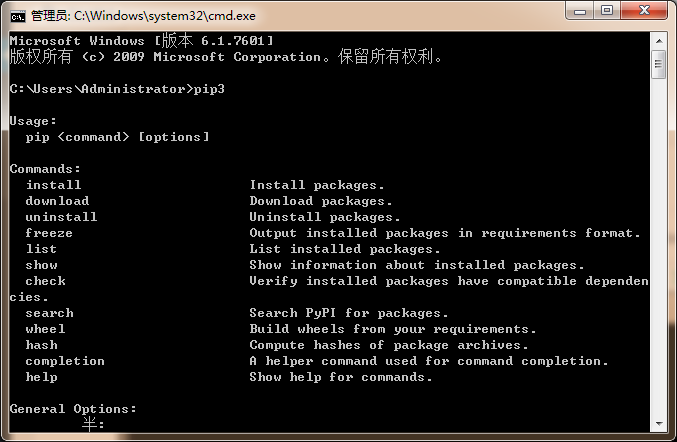
确定pip3安装成功后,我们接下来进行安装BeautifulSoup4,在dos框下输入pip3 install beautifulsoup4,回车等待。然后出现如下信息,即表示安装成功。
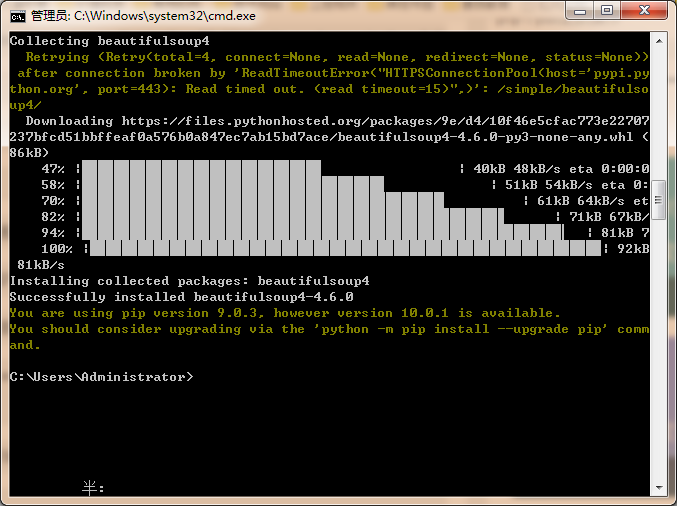
BeautifulSoup4是好用的HTML解析器,这个库在后面的博文中,我们将进行详细的介绍,这里先用着。
3.安装lxml库
lxml是第三方的,这个是解析xml或者HTML文件的第三方库,这个也需要我们自己使用pip3 安装一下。安装过程也很简单:dos框下输入pip3 install lxml等待安装完成即可。这里的第三方库文件都安装到特定的文件夹,在python编程中可以直接import即可。目前我们学的比较浅,不需要深究呢。后面的博文将深入探讨第三方模块库的安装路径,以及lxml库和BeautifulSoup4的详细说明。
2.开始抓CSDN的数据包
这里首先说明,csdn网站链接使用的是https协议,使用fiddler软件抓https的时候,需要配置一下才能开始抓https的数据包。首先选择tools,然后点击option,进行配置。
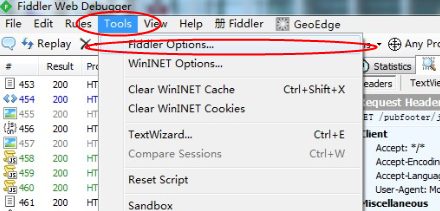
打开HTTPS配置项,勾选“CaptureHTTPS CONNECTs”,同时勾选“Decrypt HTTPS traffic”,弹出的对话框选择是(这里是按照fiddler自己的证书)如果跟我一样手机跟电脑是用wifi进行链接的话还需要选择“…fromremote clients only”。如果需要监听不可信的证书的HTTPS请求的话,需要勾选“Ignore servercertificate errors”。
这两步完成,基本上既可以抓https的数据包了。下面开始,关闭浏览器所有页面,只打开csdn登陆页面,然后清除fiddler所有连接信息,清除所有,便于登陆的时候抓包。
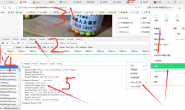
清除完信息后,在CSDN登陆页面,输入账号和密码进行登陆设置操作,抓包开始。登陆成功后,打开fiddler页面,找到passport.csdn.net域名,然后点击,在右侧即可看到相关的数据包。
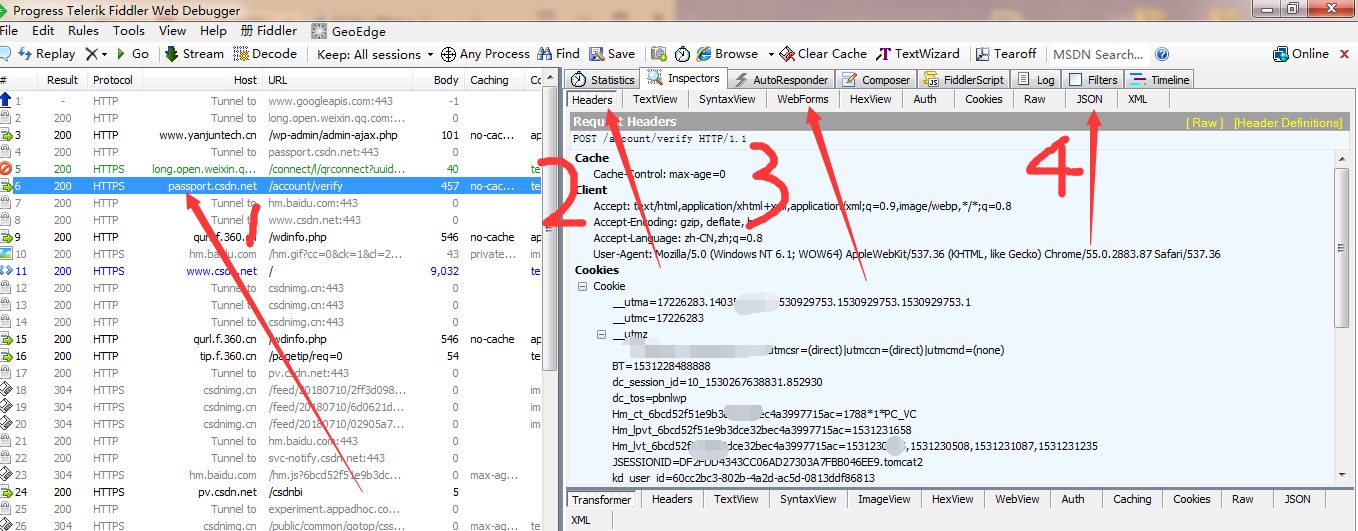
这里的2 是包含着请求头的相关信息,这里请求头中Accept-Encoding: gzip, deflate, br这一行,代表着数据使用的是gzip压缩技术,所以返回的数据需要进行相应的解压操作才能被正常查看,爬虫将要设置这部分请求头的信息,用于模拟浏览器的操作。3这部分是包含着登陆信息的表格。4部分是登陆成功后返回的数据。关于请求头的内容,将在第六篇博文中详细介绍。
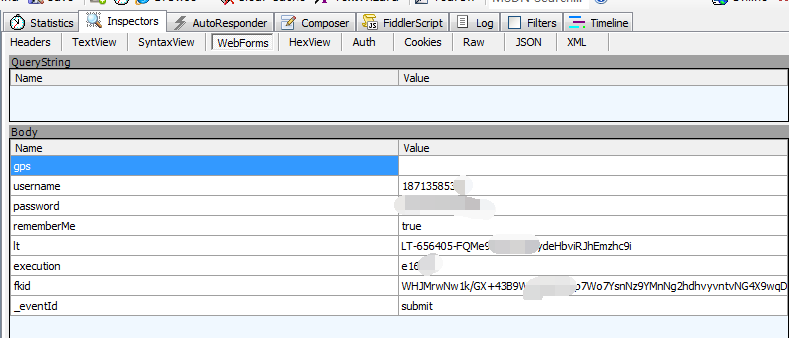
好的这里,我们就看到了csdn登陆操作登陆提交给服务器的表单中的内容如下:
- username
- password
- It
- execution
- fkid
- _eventId
这里CSDN的登陆比较复杂,咱们使用浏览器打开csdn登陆页面,然后鼠标右键查看源代码找到如下登陆部分代码

该参数可以理解成每个需要登录的用户都有一个流水号。只有有了webflow发放的有效的流水号,用户才可以说明是已经进入了webflow流程。否则,没有流水号的情况下,webflow会认为用户还没有进入webflow流程,从而会重新进入一次webflow流程,从而会重新出现登录界面。
所以我们爬虫模拟登陆的时候,需要设置这几个表单,需要获取一下当前登陆的流水号。一般的网站登陆并没有流水号,所以登陆会比较简单,但是这里CSDN需要获取一下,所以稍微有点复杂。
3. 模拟登陆CSDN的Python代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
from bs4 import BeautifulSoup #导入cookies库 import http.cookiejar #导入url解析库 import urllib.parse #导入gzip进行解压缩 import gzip #设置请求头信息的方法 def setHeader(head,opener): header = [] for key, value in head.items(): elem = (key, value) header.append(elem) opener.addheaders = header # 定义一个方法来解压返回信息 def ungzip(data): try: # 尝试解压 print('正在解压.....') data = gzip.decompress(data) print('解压完毕!') except: print('未经压缩, 无需解压') return data # 封装头信息,伪装成浏览器 这部分是抓包获得的请求头信息 header = { 'Connection': 'Keep-Alive', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'X-Requested-With': 'XMLHttpRequest', } # CSDN的登陆网站 login_csdn = "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn" # 使用cookies 进行登陆操作,在下一篇博文中将重点介绍cookies,这篇仅会用即可 cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro) #模拟链接一次,获取html数据 解析出流水号 response = opener.open(login_csdn) id = '你的账号' # 你的用户名 password = '你的密码' # 你的密码 soup = BeautifulSoup(response.read(),'lxml') # 获取登入页面的input标签中lt的值,后面post表单上传登入信息需要 lt = soup.select('input[name="lt"]')[0]['value'] # 获取登入页面的input标签中execution的值,后面post表单上传登入信息需要 execution = soup.select('input[name="execution"]')[0]['value'] #csdn登录表单 需要流水号 postDict = { 'username': id, 'password': password, "lt": lt, "execution": execution, "_eventId": "submit" } #设置请求头 开始准备登陆到csdn setHeader(header, opener) #将表单数据进行 url编码 postData = urllib.parse.urlencode(postDict).encode() #使用post方式,登陆到CSDN op = opener.open(login_csdn, postData) #登陆后我们随意跳转到博客到我自己的博客页面 url = "https://blog.csdn.net/zzw5945/article/details/80955268" result = opener.open(url) #获取到登陆成功后的数据 data = result.read() #将gzip数据 进行解压缩,然后解码成utf-8的数据 data = ungzip(data).decode(encoding='utf-8', errors='strict') #将数据打印出调试框 print(data) |
使用pycharm运行之后,调试框出现如下信息,即代表登陆成功,然后转到了相应的页面。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
D:\python\python.exe E:/技术学习/Python代码/6.登录csdn/login_csdn.py 正在解压..... 解压完毕! <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <link rel="canonical" href="https://blog.csdn.net/zzw5945/article/details/80955268"/> <meta http-equiv="content-type" content="text/html; charset=utf-8"> <meta name="renderer" content="webkit"/> <meta name="force-rendering" content="webkit"/> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/> <meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no"> <meta name="apple-mobile-web-app-status-bar-style" content="black"> <meta name="referrer" content="always"> <meta name="description" content="西门子WINCC7.2软件+破解视频教程百度网盘资源下载 西门子wincc flexible触摸屏入门及应用视频教程 西门子wincc触摸屏应用技术视频教程_阳胜峰_7讲 西门子官网系列视频:WinCC Flexible跟我做 西门子官网系列视频教程百度云资源下载:WinCC Flexible跟我学_51讲 西门子触摸屏入门及应用视频教程资料百度网盘资源下载_梁智彬_66讲(高..." /> |
4.总结
这一篇博文带大家简单看一下登陆CSDN这个项目,让大家了解一下简单基本的几个库。下一篇博文将为大家呈现如下内容:
- Header请求结构
- Header响应结构形式
- header头域介绍
- 通用头简介
- request请求头介绍
- response请求头介绍
转载请注明:燕骏博客 » Python3.6爬虫入门自学教程之五:小项目模拟登陆CSDN(urllib高级用法)
赞赏作者 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏