Python3.6爬虫入门自学教程之六:http请求中的header请求头相关知识
本篇博文将带大家学习以下内容:
- Header请求结构
- Header响应结构形式
- header头域介绍
- 通用头简介
- request请求头介绍
- response请求头介绍
- 上一篇博文中的header
- 本章小结
第7篇博文再带大家看cookies相关知识,并升级第五篇博文中的登陆CSDN代码。
HTTP(HyperTextTransferProtocol) 即超文本传输协议,目前网页传输的的通用协议。HTTP协议采用了请求/响应模 型,浏览器或其他客户端发出请求,服务器给与响应。就整个网络资源传输而言,包括message-header和message-body两部分。首先传 递message-header,即http header消息 。http header 消息通常被分为4个部分:general header, request header, response header, entity header(请求行/状态行、头域(请求头部/响应头部)、空行、实体(请求实体/响应实体))。
以下请求头 header的查看是通过浏览器,开发者工具进行查看的,也可以通过fiddler抓包软件进行查看。这里以360浏览器为例,讲解如何查看当前网页的header。打开一个网页,然后如下图所示打开360浏览器的开发者选项:
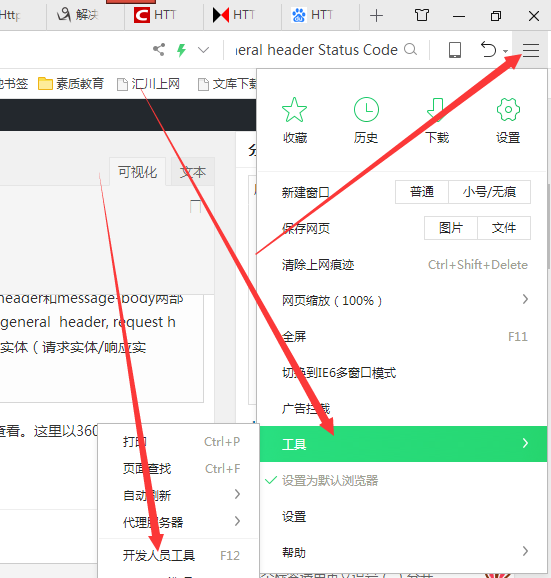
然后点击network,准备查看header。打开network时,左下方侧是当前浏览器的网络连接。如果是在这个网页新开的开发者选项,网络连接框中是没有内容的。接下来,要点击浏览器上的url连接框刷新当前的网页。然后就能看到左侧网络连接情况了。因为网页很复杂,有很多链接,所以左侧网络链接数很多。咱们点击第一个就能看到当前网页的header相关信息了。
1.http请求结构形式
http请求结构形式如下:
|
1 2 3 4 |
<Request-Method> <Request-URL> <Http-Version> //请求行(用于请求报文) <Headers> <Entity-Body> |
http请求实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
POST /jsswxxSSI/watershed_selectStrongWatershedJson.action HTTP/1.1 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Encoding:gzip, deflate, sdch, br Accept-Language:zh-CN,zh;q=0.8 Cache-Control:max-age=0 Connection:keep-alive Cookie:UM_distinctid=16469aadadc1da-04d370d36fde1b-6b1b1279-100200-16469aadadd77; wordpress_test_cookie=WP+Cookie+check; Hm_lvt_3ef185224776ec2561c9f7066ead4f24=1531121945,1531131244,1531138179,1531142350; Hm_lpvt_3ef185224776ec2561c9f7066ead4f24=1531270287; CNZZDATA1253486800=1356036522-1530777870-https%253A%252F%252Fblog.csdn.net%252F%7C1531268046 Host:yanjuntech.com Upgrade-Insecure-Requests:1 User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 [Form Data ...] //提交的请求数据 |
2.http响应结构形式
|
1 2 3 4 |
<Http-Version> <Status-Code> <Reason-Phrase> //状态行(用于响应报文) <Headers> <Entity-Body> |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
HTTP/1.1 200 OK Cache-Control:max-age=3, must-revalidate Connection:keep-alive Content-Encoding:gzip Content-Type:text/html; charset=UTF-8 Date:Wed, 11 Jul 2018 00:54:25 GMT Server:nginx/1.10.3 (Ubuntu) Transfer-Encoding:chunked Vary:Accept-Encoding, Cookie WP-Super-Cache:Served supercache file from PHP [Response Data ...] //接收的响应数据 |
3.http头域介绍
通常HTTP消息包括客户机向服务器的请求消息和服务器向客户机的响应消息。这两种类型的消息请求行/状态行、头域(请求头部/响应头部)、空行、实体(请求实体/响应实体)。上面HTTP的介绍里我们已经举过例子。
HTTP的头域包括通用头(general header),请求头(request header),响应头(response header)和实体头(entity header)四个部分。每个头域由一个域名,冒号(:)和域值三部分组成。域名是大小写无关的,域值前可以添加任何数量的空格符,头域可以被扩展为多行,在每行开始处,使用至少一个空格或制表符。
1.通用头
被Request和Response共享的Headers称为General Headers
|
1 2 3 4 5 6 7 8 9 |
general-header = Cache-Control | Connection | Date | Pragma | Trailer | Transfer-Encoding | Upgrade | Via | Warning |
- Cache -Control指定请求和响应遵循的缓存机制。
- Connection 允许客户端和服务器指定与请求/响应连接有关的选项
- Date 提供日期和时间标志,说明报文是什么时间创建的
- Pragma头域用来包含实现特定的指令,最常用的是Pragma:no-cache
- Trailer 如果报文采用了分块传输编码(chunked transfer encoding) 方式,就可以用这个首部列出位于报文拖挂(trailer)部分的首部集合
- Transfer-Encoding 告知接收端为了保证报文的可靠传输,对报文采用了什么编码方式
- Upgrade 给出了发送端可能想要”升级”使用的新版本和协议
- Via 显示了报文经过的中间节点
2.request请求头
|
1 2 3 4 5 6 7 8 9 |
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Encoding:gzip, deflate, sdch, br Accept-Language:zh-CN,zh;q=0.8 Cache-Control:max-age=0 Connection:keep-alive Cookie:UM_distinctid=16469aadadc1da-04d370d36fde1b-6b1b1279-100200-16469aadadd77; wordpress_test_cookie=WP+Cookie+check; Hm_lvt_3ef185224776ec2561c9f7066ead4f24=1531121945,1531131244,1531138179,1531142350; Hm_lpvt_3ef185224776ec2561c9f7066ead4f24=1531270287; CNZZDATA1253486800=1356036522-1530777870-https%253A%252F%252Fblog.csdn.net%252F%7C1531268046 Host:yanjuntech.cn Upgrade-Insecure-Requests:1 User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 |
- Accpet:浏览器可以接受的数据类型。Accept:text/html这个就代表,浏览器端可以接受text/html文件。如果请求发过去之后,服务器响应的数据不是text/html文件,则服务器应该返回一个406错误(non acceptable)。通配符 * 代表任意类型例如 Accept: */* 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)。q是权重系数,范围 0 =< q <= 1,q 值越大,请求越倾向于获得其“;”之前的类型表示的内容,若没有指定 q 值,则默认为1,若被赋值为0,则用于提醒服务器哪些是浏览器不接受的内容类型。
- Accept-Encoding:浏览器指定的自己支持的编码格式。通常指的是自己是否支持压缩方法,支持什么压缩方法。其中gzip, deflate, sdch, br这四种都是常用的压缩方法,gzip用的应该是最多的。
- Accept-Language:表明浏览器接收的语言类型zh-CN,zh;代表中文,q是权重系数,0<q<1,越接近1说明浏览器越希望接收到这种语言的信息。
- Cache-Control:我们网页的缓存控制是由HTTP头中的“Cache-control”来实现的,常见值有private、no-cache、max-age、must-revalidate等,默认为private。具体信息可以参考下面这篇博文:https://blog.csdn.net/fighting_tl/article/details/79300363
- Connection:keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。也就是保持当前的TCP链接不断开,如果是close则下次访问的时候重新建立tcp链接。tcp链接建立过程需要三次握手,需要消耗时间的。这里使用keep-alive可以提高效率。
- Cookie:用于验证用户信息,有的服务器在用户登录的时候,需要记录cookies信息,用于判断是否是正常的登陆。这样能提高安全性。关于cookies的重点介绍,请看下一篇博文,python3.6爬虫教程之七cookies应用介绍
- Host:请求报头域,主要是用来指定将要请求的主机位置和访问端口。如果host后没有指定端口,则默认的访问端口是80端口。host中的信息一般是从URL中解析而来
- User-Agent:用来告诉服务器当前浏览器的版本和名称,同时也告诉了服务器当前的客户端使用的操作系统环境。
这里还有很多request请求头的参数。这里请大家参考如下博文:https://blog.csdn.net/alanlzz/article/details/72846718
3.response响应头头域
|
1 2 3 4 5 6 7 8 9 |
Accept-Ranges:none Cache-Control:max-age=864000, must-revalidate Connection:keep-alive Content-Length:4786 Content-Type:image/jpeg Date:Wed, 11 Jul 2018 00:51:27 GMT Expires:Sat, 21 Jul 2018 00:51:27 GMT Last-Modified:Wed, 11 Jul 2018 00:51:27 GMT Server:nginx/1.10.3 (Ubuntu) |
- Accept-Ranges:表明服务器是否支持指定范围请求及哪种类型的分段请求
- Cache-Control:告诉所有访问的设备是否可以缓存,以及支持何种缓存类型
- Connection:客户端访问当前服务器后,如果不关闭网页,则当前TCP链接一直保持存活状态,方便下一次的连接。
- Date:原始服务器消息发出的时间
这里很多参数,就不一一写了,请参见下面的博文:https://blog.csdn.net/alanlzz/article/details/72846718
4.上一篇博文的代码中的header
|
1 2 3 4 5 6 7 8 9 |
# 封装头信息,伪装成浏览器 这部分是抓包获得的请求头信息 header = { 'Connection': 'Keep-Alive', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'X-Requested-With': 'XMLHttpRequest', } |
这段代码主要功能就是将爬虫,模拟成浏览器。让服务器通过爬虫的请求,从而让爬虫获取到数据。这里使用的就是上面博文中request请求头部分的内容。
5.本篇小结
这篇博文,带大家简单了解了http请求相关知识。基本知道了http请求头相关参数的意义和用法。下一篇博文将和大家一起学习cookies相关的知识内容。
转载请注明:燕骏博客 » Python3.6爬虫入门自学教程之六:http请求中的header请求头相关知识
赞赏作者 微信赞赏
微信赞赏 支付宝赞赏
支付宝赞赏